Copied from Softmax Temperature
Temperature is a hyperparameter of LSTMs (and neural networks generally) used to control the randomness of predictions by scaling the logits before applying softmax. Temperature scaling has been widely used to improve performance for NLP tasks that utilize the Softmax decision layer. For explaining its utility, we will consider the case of Natural Language Generation, wherein we need to generate text by sampling out novel sequences from the language model (using the decoder part of the seq-to-seq architecture). At each time step in the decoding phase, we need to predict a token, which is done by sampling from a softmax distribution (over the vocabulary) using one of the sampling techniques. In short, once the logits are obtained, the quality and the diversity of the predictions is controlled by the softmax distribution and the sampling technique applied thereupon. This article is about tweaking the softmax distribution to control how diverse and novel the predictions are. The latter will be covered in a future article.
Fig 1 is a snapshot of how the prediction is made at one of the intermediate timesteps in the decoding phase.
![]()
But what is the issue here?
The generated sequence will have a predictable and generic structure. And the reason is less entropy or randomness in the softmax distribution, in the sense that the likelihood of a particular word (corresponding to index 9 in the above example) getting chosen is way higher than the other words. A sequence being predictable is not problematic as long as the aim is to get realistic sequences. But if the goal is to generate a novel text or an image which has never been seen before, randomness is the holy grail.
The Solution?
Increase the randomness. And that’s precisely what Temperature scaling does. It characterizes the entropy of the probability distribution used for sampling, in other words, it controls how surprising or predictable the next word will be. The scaling is done by dividing the logit vector by a value T, which denotes the temperature, followed by the application of softmax.
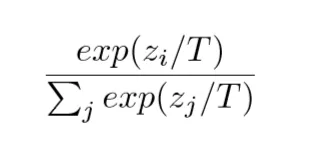
The effect of this scaling can be visualized in Fig 3: 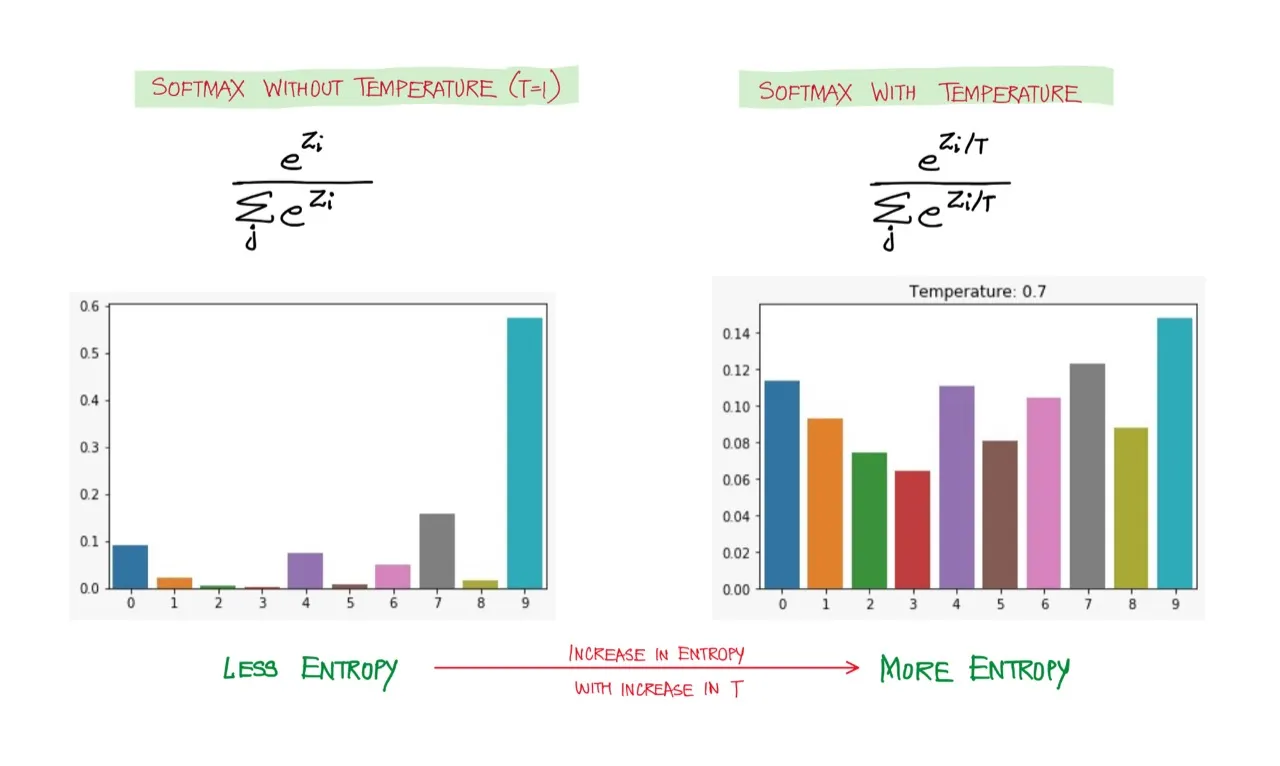
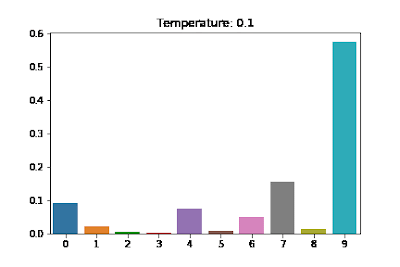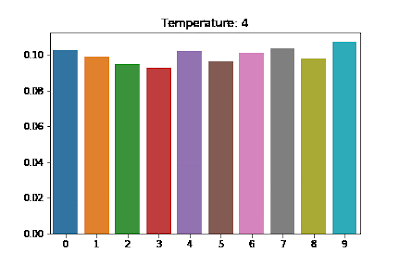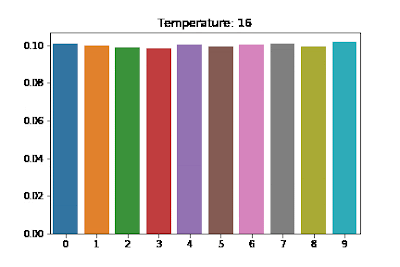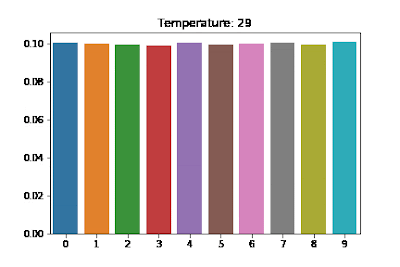
The distribution above approaches uniform distribution giving each word an equal probability of getting sampled out, thereby rendering a more creative look to the generated sequence. Too much creativity isn’t good either. In the extreme case, the generated text might not make sense at all. Hence, like all other hyperparameters, this needs to be tuned as well.
Conclusion
The scale of temperature controls the smoothness of the output distribution. It, therefore, increases the sensitivity to low-probability candidates. As \(T \rightarrow \infty\), the distribution becomes more uniform, thus increasing the uncertainty. Contrarily, when \(T \rightarrow 0\), the distribution collapses to a point mass. As mentioned earlier, the scope of Temperature Scaling is not limited to NLG. It is also used to calibrate deep learning models while training and in Reinforcement Learning as well. Another broader concept that it is a part of is Knowledge Distillation. Below are the links on these topics for further exploration.
Author: Harshit Sharma Source