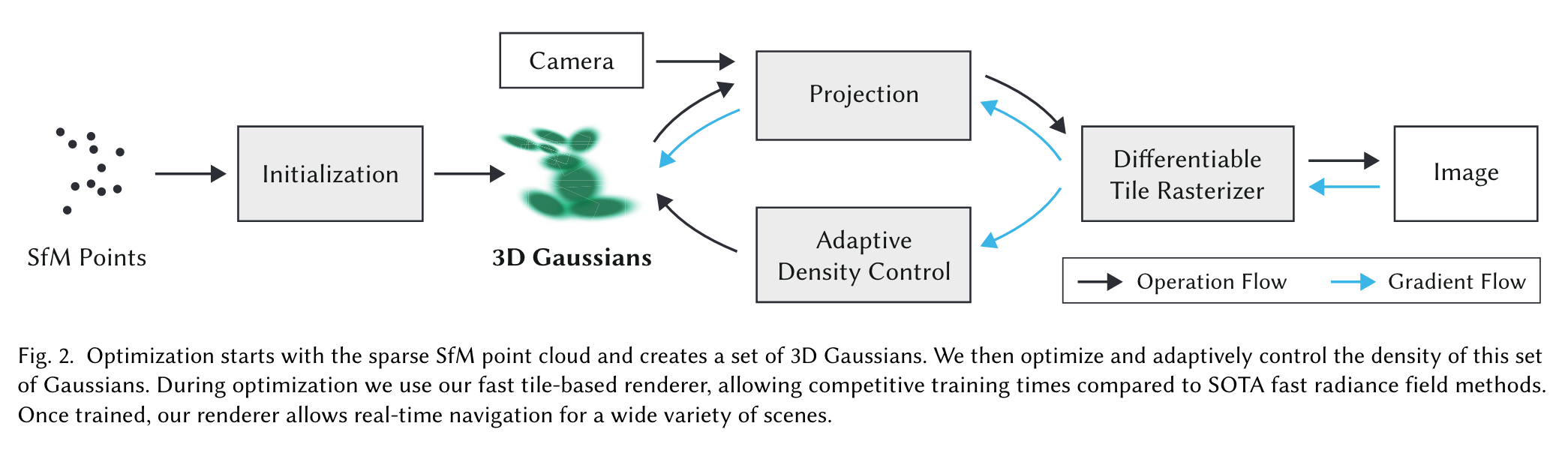
Code
Clone the github
1
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
Setup
1
2
conda env create --file environment.yml
conda activate gaussian_splatting
Notes Theu cuda version must $\geq 11.8$ And then you need to install submodules
1
2
pip install -q gaussian-splatting/submodules/diff-gaussian-rasterization
pip install -q /content/gaussian-splatting/submodules/simple-knn
Dataset
1
2
wget https://huggingface.co/camenduru/gaussian-splatting/resolve/main/tandt_db.zip
unzip tandt_db.zip
Train
1
python train.py -s gaussian-splatting/tandt/train
Eval
1
2
3
python render.py -m <path to trained model>
python render.py -m <path to pre-trained model> -s <path to COLMAP dataset>
python metrics.py -m <path to pre-trained model>
<path to trained model> may be outputs/xxxx
Code Explanation
Train.py
model: GaussianModel (variable: gaussians) dataset: Scene (variable: scene) render: render (function: render, defined in gaussian_renderer)
1
2
bg_color = [1, 1, 1] if dataset.white_background else [0, 0, 0]
background = torch.tensor(bg_color, dtype=torch.float32, device="cuda")
1
viewpoint_stack = None
1
2
3
# Every 1000 its we increase the levels of SH up to a maximum degree
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
1
render_pkg = render(viewpoint_cam, gaussians, pipe, bg)
Training:
1
2
3
4
5
6
7
8
gaussians.update_learning_rate(iteration) # adjust the learning rate
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1)) # pick a random camera
bg = torch.rand((3), device="cuda") if opt.random_background else background # set the background color
render_pkg = render(viewpoint_cam, gaussians, pipe, bg) # render process
image, viewspace_point_tensor, visibility_filter, radii = render_pkg["render"], render_pkg["viewspace_points"], render_pkg["visibility_filter"], render_pkg["radii"] # get rendered outputs
loss = (1.0 - opt.lambda_dssim) * Ll1 + opt.lambda_dssim * (1.0 - ssim(image, gt_image)) # loss (reconstruction loss + ssim loss)
The directional appearance component (color) of the radiance field is represented via spherical harmonics (SH)
Spherical harmonic lighting (SH coefficients)
1
2
3
# Every 1000 its we increase the levels of SH up to a maximum degree
if iteration % 1000 == 0:
gaussians.oneupSHdegree()
Densification:
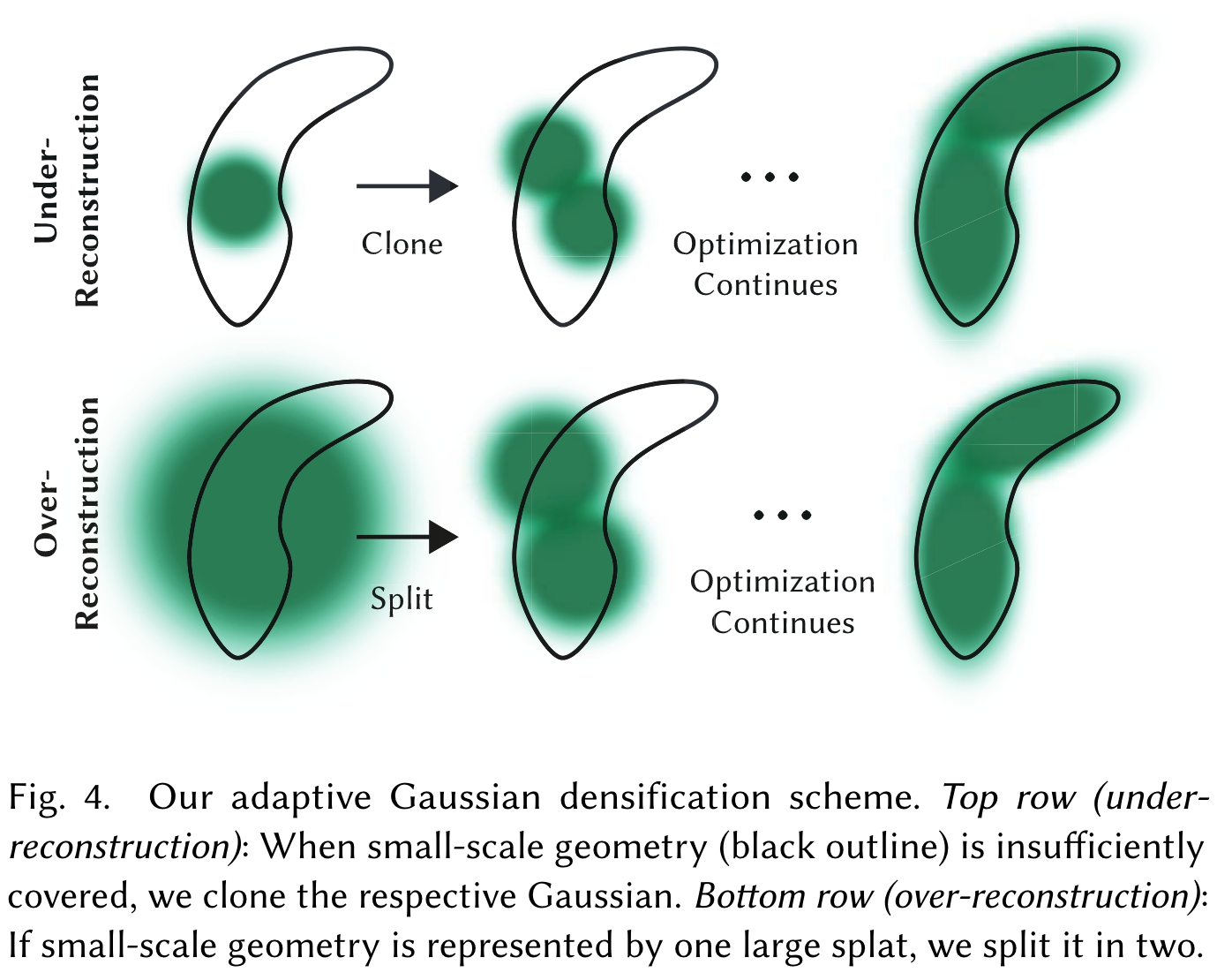
1
2
3
4
5
6
7
8
9
10
11
12
# Densification
if iteration < opt.densify_until_iter:
# Keep track of max radii in image-space for pruning
gaussians.max_radii2D[visibility_filter] = torch.max(gaussians.max_radii2D[visibility_filter], radii[visibility_filter])
gaussians.add_densification_stats(viewspace_point_tensor, visibility_filter)
if iteration > opt.densify_from_iter and iteration % opt.densification_interval == 0:
size_threshold = 20 if iteration > opt.opacity_reset_interval else None
gaussians.densify_and_prune(opt.densify_grad_threshold, 0.005, scene.cameras_extent, size_threshold)
if iteration % opt.opacity_reset_interval == 0 or (dataset.white_background and iteration == opt.densify_from_iter):
gaussians.reset_opacity()
Model
Arguments
1
2
3
4
5
6
7
8
9
self._xyz, # spatial position
self._features_dc,
self._features_rest,
self._scaling, # scaling of ellipsoids
self._rotation, # rotation of ellipsoids
self._opacity, # opacity
self.max_radii2D,
self.xyz_gradient_accum
self.denom
Crucial funstions:
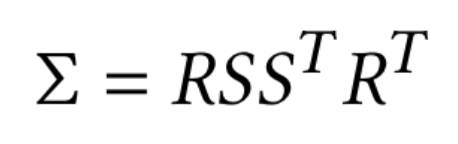
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# s: scaling matrix, r: rotation matrix
def build_scaling_rotation(s, r):
L = torch.zeros((s.shape[0], 3, 3), dtype=torch.float, device="cuda")
R = build_rotation(r)
L[:,0,0] = s[:,0]
L[:,1,1] = s[:,1]
L[:,2,2] = s[:,2]
# L: 3x3, R: 3x3
L = R @ L
return L
def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation):
L = build_scaling_rotation(scaling_modifier * scaling, rotation) #
actual_covariance = L @ L.transpose(1, 2)
symm = strip_symmetric(actual_covariance) 3x3 -> 6
return symm
Actual_covariance is the symmetric matrix so that we get the upper right part.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# get the upper triangular matrix
def strip_lowerdiag(L):
uncertainty = torch.zeros((L.shape[0], 6), dtype=torch.float, device="cuda")
uncertainty[:, 0] = L[:, 0, 0]
uncertainty[:, 1] = L[:, 0, 1]
uncertainty[:, 2] = L[:, 0, 2]
uncertainty[:, 3] = L[:, 1, 1]
uncertainty[:, 4] = L[:, 1, 2]
uncertainty[:, 5] = L[:, 2, 2]
return uncertainty
def strip_symmetric(sym):
return strip_lowerdiag(sym)
Scaling_matrix: 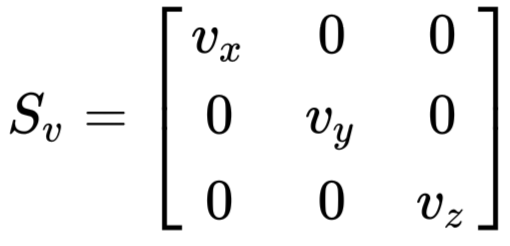
A quaternion q to represent rotation q with real part $q_r$ and imaginary parts $q_i, q_j, and q_K$ to a rotation matrix R: 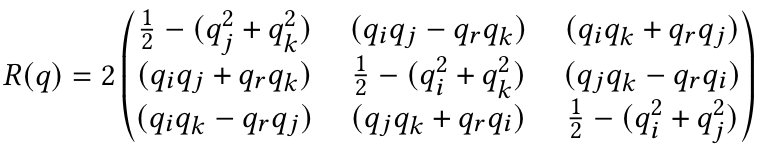
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def build_rotation(r):
norm = torch.sqrt(r[:,0]*r[:,0] + r[:,1]*r[:,1] + r[:,2]*r[:,2] + r[:,3]*r[:,3])
q = r / norm[:, None]
R = torch.zeros((q.size(0), 3, 3), device='cuda')
r = q[:, 0]
x = q[:, 1]
y = q[:, 2]
z = q[:, 3]
R[:, 0, 0] = 1 - 2 * (y*y + z*z)
R[:, 0, 1] = 2 * (x*y - r*z)
R[:, 0, 2] = 2 * (x*z + r*y)
R[:, 1, 0] = 2 * (x*y + r*z)
R[:, 1, 1] = 1 - 2 * (x*x + z*z)
R[:, 1, 2] = 2 * (y*z - r*x)
R[:, 2, 0] = 2 * (x*z - r*y)
R[:, 2, 1] = 2 * (y*z + r*x)
R[:, 2, 2] = 1 - 2 * (x*x + y*y)
return R
Point Cloud Data (pcd) processing:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def create_from_pcd(self, pcd: BasicPointCloud, spatial_lr_scale: float):
self.spatial_lr_scale = spatial_lr_scale
fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda()
fused_color = RGB2SH(torch.tensor(np.asarray(pcd.colors)).float().cuda())
features = torch.zeros((fused_color.shape[0], 3, (self.max_sh_degree + 1) ** 2)).float().cuda()
features[:, :3, 0 ] = fused_color
features[:, 3:, 1:] = 0.0
print("Number of points at initialisation : ", fused_point_cloud.shape[0])
dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)
scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)
rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")
rots[:, 0] = 1
opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))
self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))
self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))
self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(True))
self._opacity = nn.Parameter(opacities.requires_grad_(True))
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size):
grads = self.xyz_gradient_accum / self.denom # calculate the gradients of estimated density
grads[grads.isnan()] = 0.0
self.densify_and_clone(grads, max_grad, extent) # density and clone for under reconstrution areas
self.densify_and_split(grads, max_grad, extent) # density and split for over reconstrution areas
prune_mask = (self.get_opacity < min_opacity).squeeze() # mask points with opacity smaller than threshold
if max_screen_size:
big_points_vs = self.max_radii2D > max_screen_size # mark points with radius greater than threshold
big_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extent # mark points with scales greater than threshold
prune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws) # get the final prune mask
self.prune_points(prune_mask) # prune parameters
torch.cuda.empty_cache() # clear the GPU cache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def densification_postfix(self, new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation):
d = {"xyz": new_xyz,
"f_dc": new_features_dc,
"f_rest": new_features_rest,
"opacity": new_opacities,
"scaling" : new_scaling,
"rotation" : new_rotation}
optimizable_tensors = self.cat_tensors_to_optimizer(d)
self._xyz = optimizable_tensors["xyz"]
self._features_dc = optimizable_tensors["f_dc"]
self._features_rest = optimizable_tensors["f_rest"]
self._opacity = optimizable_tensors["opacity"]
self._scaling = optimizable_tensors["scaling"]
self._rotation = optimizable_tensors["rotation"]
self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")
self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
作者:lingjivoo,github主页:传送门